


梦晨 发自 凹非寺
量子位 | 公众号 QbitAI复刻OpenAI o1推理大模子,开源界传来最新阐明:
LLaMA版o1容貌刚刚发布,来自上海AI Lab团队。
简介中明确:使用了蒙特卡洛树搜索,Self-Play强化学习,PPO,以及AlphaGo Zero的双重战略范式(先验战略+价值评估)。

在2024年6月,o1发布之前,团队就开动探索蒙特卡洛树搜索晋升峻模子数学才调,累积了一些温煦。
此次最新开源代码,也在缔造者社区引起热议。
OpenAI o1系列发布后,团队开动升级算法,专注于数学奥赛问题,动作OpenAI草莓容貌标开源版块。
10月初,团队上传新论文,使用成对优化(抵御直给出足够分数,而是比拟两个谜底的相对优劣)晋升Llama模子数学奥赛才调。
在最难的AIME2024基准测试30谈题中,原版LLaMA-3.1-8B-Instruct作念对2谈,优化后作念对8谈,跨越了除o1-preview和o1-mini以外的其他贸易闭源决策。

10月底,团队文告在基于AlphaGo Zero架构复刻OpenAI o1的发愤中取得了要紧阐明:
已得胜使模子在学习经由中通过与搜索树交互赢得高档念念维才调,无需东谈主工标注。
不到一周时候,容貌便开源了。

LLaMA版o1最新阐明
现在已开源本体包括:预磨练数据集、 预磨练模子、强化学习磨练代码。
OpenLongCoT-Pretrain数据集,包含10万+条长念念维链数据。
每条数据包含一个完竣的数知识题推理经由,包含念念考本体和评分舍弃。
举例一个几何问题,包含了问题形色、图形坐标、策动经由和论断推导等完竣的推理链路,以及对各个推理门径的月旦和考据本体,对推理经由进行评价和指引。

在此数据集链接预磨练后,模子可读取和输出近似o1的长念念维链经由。
预磨练代码尚未发布,现在保举使用LLaMaFactory代替。
额外旨道理的是天然容貌名为LLaMA-O1,但现在官方给的预磨练模子基于谷歌Gemma 2。

现在在预磨练模子基础上,不错链接进行强化学习磨练,从代码中不错看出磨练经由如下:
使用蒙特卡洛树搜索进行自我对弈(self-play)以生成训导将训导存储在优先训导回放缓冲区中从缓冲区采样批次数据进行磨练更新模子参数和训导优先级论文中也给出了磨练经由的图示。
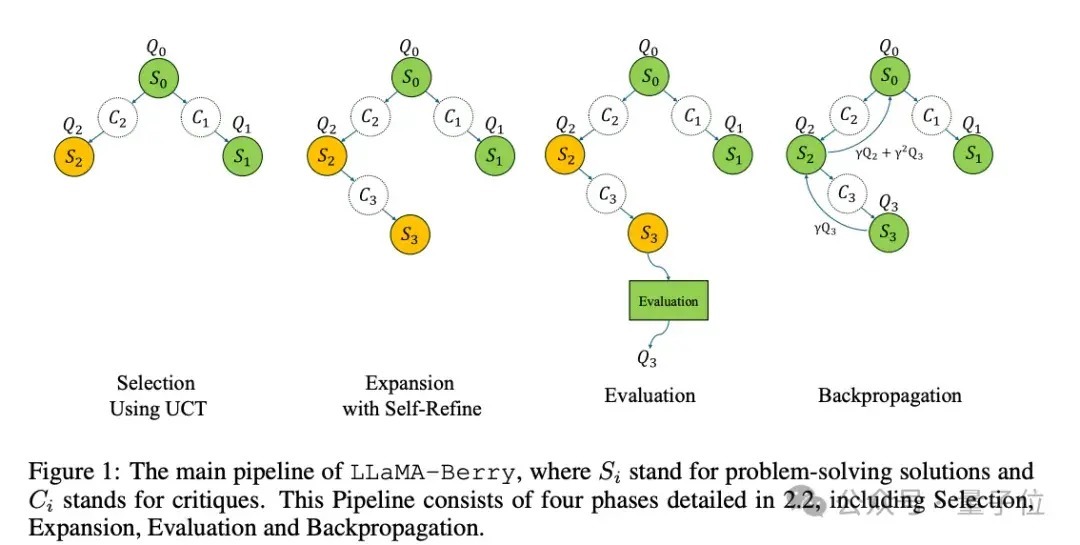
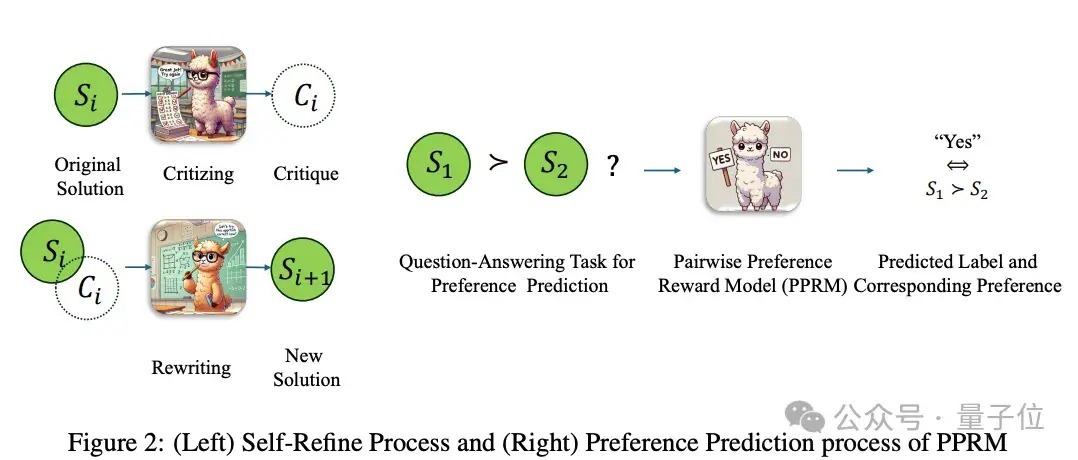
同期磨练代码中使用了以下要害技巧点:
使用LoRA进行参数高效微调使用PPO算法动作战略优化门径收场了GAE(Generalized Advantage Estimation)算法用于策动上风函数使用优先训导回放晋升磨练就果终末,LLaMA-O1代码发布在名为SimpleBerry的GitHub账号下,并莫得很是简介,还比拟好意思妙。
其他与SimpleBerry相关的账号和官网中,只可看出性质是一个盘问执行室,也并未炫夸更多盘问标的信息。

其他o1复刻容貌阐明
除LLaMA-O1以外,另一个公开阐明的o1复刻容貌O1-Journey来自上交大团队。
团队在十月初发布了第一份阐明证明,其中先容了立异Journey Learning范式,以选取一个得胜将搜索和学习整合到数学推理中的模子。

O1-Journey中枢缔造团队主要由上交大大三、大四本科生,以及上交大GAIR执行室(生成式东谈主工智能盘问执行室)的一年事博士生构成。
指引教练包括上交大副教训刘鹏飞,姚班学友、斯隆奖得主李远志等。

LLaMA-O1:
https://github.com/SimpleBerry/LLaMA-O1干系论文:https://arxiv.org/abs/2406.07394https://arxiv.org/abs/2410.02884O1-Journey:
https://github.com/GAIR-NLP/O1-Journey/— 完 —
量子位 QbitAI · 头条号签约
温煦咱们,第一时候获知前沿科技动态